SWETグループの平田(@tarappo)です。
10/21(木)にiOS Test TeaTime #3を開催しました。
その時の私の登壇資料は次のとおりです。
資料では不足しているであろう情報もあるので、本稿ではその点も補いつつ説明していきたいと思います。
はじめに
SWETメンバーとして、プロジェクトに関わるときは「CI/CDサービス」が問題なく動いているかどうかを確認することはよくあります。
CI/CDサービスが文字通り継続的に動いているのであれば「プロジェクトのコードが手元でも動かせる」「コードの状態がある程度わかる」という状態ともいえます。
そのため、これはプロジェクトの状況を把握してなにをするべきかを判断するためには重要な指標の1つともいえます。
その中で最初にチェックする箇所の例としては、次のようなものがあります。
- どのようなことを実行しているか
- 自動テストがあって実行されているか
- どのようなタイミングで実行しているか
- 継続的に動かせているか
- ビルドの成功率はどういった状態か
- 仮に失敗をある程度していてもすぐ直せているか
本稿では、私が今回関わったプロジェクトの「関わった頃の状況」とそれを元にどのような理由からどのようなことをおこなっていったかについて次から説明をしていきます。
関わった頃の状況
本稿で話す関わったプロジェクトではiOS周りをメインで関わりました。 そのプロジェクトで利用しているCI/CDサービスはBitriseになります。
Bitriseの詳細は本稿では説明をしませんが、Bitriseでは実行するものを「ワークフロー」という単位で用意します。 その「ワークフロー」は特定の機能をおこなうことができる「ステップ」と呼ばれるものを組み合わせて作ります。
このBitriseの関わった頃の利用状況としては次のようなものでした。
- Q:どのようなことを実行しているか
- 一般的なワークフロー(ビルド、テスト、App Store Connectへのアップロード)は揃っている
- コードにテストケースは一定あるが「テスト」のワークフローはNightly実行のみ
- Q:どのようなタイミングで実行しているか
- 継続的に動かせているのは一部であり、次のような感じになっていた
- PR単位:Dangerのみ実行しており、他は実行していない
- Dangerは本プロジェクトの他リポジトリと併せてCircleCIに移行しました
- Push時(特定ブランチ):アプリのビルドと配布
- Nightly(1日1回):テスト
- PR単位:Dangerのみ実行しており、他は実行していない
- 継続的に動かせているのは一部であり、次のような感じになっていた
- Q:ワークフローの実行結果の成功率はどのぐらいか
- アプリのビルドにおいて、マージ後に直せているがテストにおいては失敗したまま放置傾向になっている
上記のように、PR単位で何かしらのワークフローは動かしておらずコードのチェックは行えていない状態ではありました。
この状態の理由
関わった頃はまだ「開発者がそこまで多くなく、みんながある程度プロダクトについて理解している状態」という前提がありました。
そのような前提がある中なので、
- Bitriseの運用に対してコストをあまりかけられない
- 「ビルド」や「テスト」が失敗するようなコードであっても、原因に気づきやすくコードを直すコストはそこまで高くない
結果として、この時点ではBitriseは「アプリの配布用」の用途ぐらいになっていました。
今後もこのような体制であれば一定問題がおきないかもしれませんが、関わった時点で人が増えつつある時期でもありました。 このまま進んでいくと、次のような問題が起こるであろうと思われました。
今後起こるであろう問題
関わる人が増えてくると、次のような問題が発生していきます。
- 手元で「ビルドができない」「テストが通らない」といったケースが増える
- 自分が関係していないコードのことが多くなり、原因の特定コストが一定かかる
- 誰もがマージできるためビルドできないコードが一定発生し「検証をするためのアプリ」のビルドが検証当日になっても出来ていないといったことが起こる
この手のことがある程度増えて、結果として「コミュニケーションコスト」「失敗の原因の特定コスト」「修正コスト」といったいくつものコストが必要になってしまうということが起こりえます。
この状態が今後起こることを想定し、Bitriseをもう少し活用し「コードの品質」をある程度担保できるようにするのが良いだろうと判断しました。
そこで、「今後に向けた対応」として次を検討しました。
- Step1:PR時点で「ビルド」「テスト」のワークフローを動かす
- Step2:「ビルド」「テスト」のワークフローが失敗したものはマージできないようにする
これらをBitriseやGitHubなどで設定することはかんたんです。 しかし、実際に利用され続けなければ意味がありません。
そこで、この「Step1」と「Step2」をおこなった場合の課題などについて関係者にヒアリングをおこないました。 その結果として次の課題がわかりました。
- 課題1:実行時間がかかりすぎて待っていることができない
- 特に「テスト」の実行時間が長い
- 課題2:必要性を強くは感じていない
- 現時点ではそこまで問題が起きていないと考えているため
実行時間がかかりすぎてもこれらを行おうとするかはプロダクトをとりまく状況にも依存します。 この時点では、スピード優先してリリースしていくという形とも言えました。
しかし「課題1」「課題2」において何かしらのアプローチをおこなうことは今後を考えると必要だろうと判断しました。 それらについて次に説明をしていきます。
課題1:実行時間について
Bitrise Insightsという機能を利用して実際に「テスト」にかかっていた時間を出すと次のとおりです。

この画像をみたら分かるとおりですが、
- テストの実行時間は40分以上
- 成功率は高くない
PR時において40分以上も結果を待つのは厳しく、1度失敗して修正するとすぐに1時間以上の時間が発生するためPR時に設定したくない理由も分かります。
また成功率の低さは手元で全テストを実行するのが面倒という側面もあったと考えられます。 本稿では詳細は割愛しますが、このプロジェクトではモジュール単位で分割しており、モジュール単位でテスト実行できるものの、それら全てのテスト実行がXcodeからできるようになっていませんでした。 ※なお、この課題については全実行できるような仕組みを別途チームメンバーが用意してくれました。
このような状況下では、テストが壊れやすくその上に壊れたテストが乗ってしまい、さらに直しづらいというループが出来てしまいます。
これらを解消するには「実行時間」をできる限り短くする必要があるといえます。
課題2:必要性の認識
「定期的にコードのチェックをしてなくても問題があまり起きていない」状況ではありますが、将来的には炎上リスクがあると言えます。
必要性を認識してもらうためには「治安の良い状態に慣れてもらう」「現状を認識できるようにする」といった状態にして、このような環境が当たり前と思ってもらうことです。
- 「Bitriseの治安の良い状態(グリーンが当たり前)」を作って、その環境に慣れてもらう
- 「Bitriseの状態の可視化」をおこないコードの状態を常にわかるようにする
このような状況を当たり前にすることで、なにか問題が発生したときに以前と比べて「問題が起きた」というのを強く感じてもらえるようにするというのがあります。
おこなったことの内容
上述した「課題1」「課題2」を解決するために行なったことについて次のとおりです。
- 前提としてやる必要のあること(まずはキレイにすること)
- (1)Bitriseのワークフローの現状把握と整理
- 「課題1」へのアプローチ
- (1)Bitriseのワークフローの現状把握と整理(一部)
- (2)実行時間の短縮
- 「課題2」へのアプローチ
- (3)情報を追えるようにするための可視化
- (4)安定運用するための対応
(1)Bitriseのワークフローの現状把握と整理
既存のワークフローの把握と整理
BitriseはWebからワークフローを簡単に作れるため、ワークフローやワークフロー内のステップは増えやすく誰が作ったか分かりづらいという問題があります*1。
結果として次のようなことがしばしば起きますし、実際に起きていました。
- 「使っていないワークフロー、ステップ」が残されたままになることがある
- 例えば、調査用に作った一時的なものは放置されやすい
- ワークフロー名に統一性がなかったり、行なっていることとワークフロー名があっていない
そこで、次の方針をもとに整理整頓を進めました
- 必要のないものは削除
- これでステップが削除されると実行時間の削減にもつながる
- ドキュメント化
- ルール化したほうが良いものについてはルールについて明記
- ワークフローやトリガーなどBirise利用に関する情報をドキュメントにまとめ、適宜更新
この方針のもとにおこなったこととしては、次のようなものです。
- (1)メンバーにヒアリング
- 使っていないワークフロー、ステップの削除
- (2)ワークフローで行なっていることをチェック
- 別名のワークフローだけど中身は同じというのもあったため整理
- 使っているステップをチェックし必要なければ削除
- (3)ワークフローの作り方についてルール化
- ワークフロー名の命名規則
- ユーティリティワークフローの用意と利用
- (4)今後のために整理した内容は全てドキュメント化
ヒアリングして削除できたものはそこまで多くなく、実際はワークフローならびにステップ、そしてステップがよんでいる先(たとえばfastlaneのlane)をチェックして、本当に必要なのかを確認しつつ進めました。
次図は実際のドキュメントの目次ですが、最終的にはこのようなドキュメントを用意することで、これから利用する人も現状把握がある程度しやすいようにしています。

これらによって現状のBitriseのワークフローなどの状態がわかるようになりました。 ここからがスタートとも言えます。
また、これらは地道な作業ですがこれだけでも多少の実行時間の削減に繋がっています。
既存のワークフローの失敗を直す
あまり定期的に動かしてないこともあり「テスト」のワークフローは失敗していました。
壊れた状態のままにしておくと、他の壊れたコードも追加されていってさらに直すのが大変になります。 結果として、放置されてしまうということはよくあることです。
あまり動かしていなかったこの「テスト」では次のような問題が起きていました。
- 例1)Compile errorになっている
- 例2)期待値が少し変更されていた(例えば表示文言が変わったとか)
- 例3)手元では動くがBitriseの環境依存で落ちる
- 例4)Xcode12 x XcodeGenで起きたCycle Inside App問題
例1)や例2)では落ちている箇所を伝えて、直してもらえれば大丈夫です。 しかし例3)や例4)は調査、対応コストが一定かかるためどうしても放置されてしまいがちです。
そこで例1)や例2)はSWETメンバーで対応はしつつも、少したったらプロジェクトメンバーに伝えて直してもらうように依頼しました。 例3)や例4)についてはSWETメンバー側でおもに関わって対応をしました。
対応をした結果、1度All Greenになりましたが再度テストが失敗することは何度も起きました。 しかし、例3)や例4)のようなコストが一定かかるものは何度も起きるわけではありません。
何度も対応を続けることで、All Greenにするための修正コストもそこまでかからないようになってきました。
(2)実行時間の短縮
「課題1」のアプローチは分かりやすく、実行時間をどれだけ減らせるかになります。
PR時にワークフローが動いている状態を当たり前にするためには、この状態が良いなと思ってもらわなくてはなりません。 そのためには、実行時間は大きな課題でした。
そこで、多少ワークフローでおこなっていることがわかりづらくなっても、実行時間を減らすことを最優先としました。
実行時間の短縮
まずは実行時間がかかっているテストをどうにかするところからはじめました。
当初のテストのワークフローの例としては次のような感じでした。
※実際のワークフローはもう少しステップが多いです。

この状態における実行時間短縮に向けた対応として次をおこないました。
- (1)並列化ができる箇所(ステップC)は並列化
- (2)並列化しても共通して利用されるステップ(C以外のステップ)で時間を減らせる箇所がないかの調査と対応
ワークフローの並列化
Bitriseでのワークフローの並列化は公式のステップを利用します。 実際に用意した並列化したワークフローの図を元に説明をしていきます。
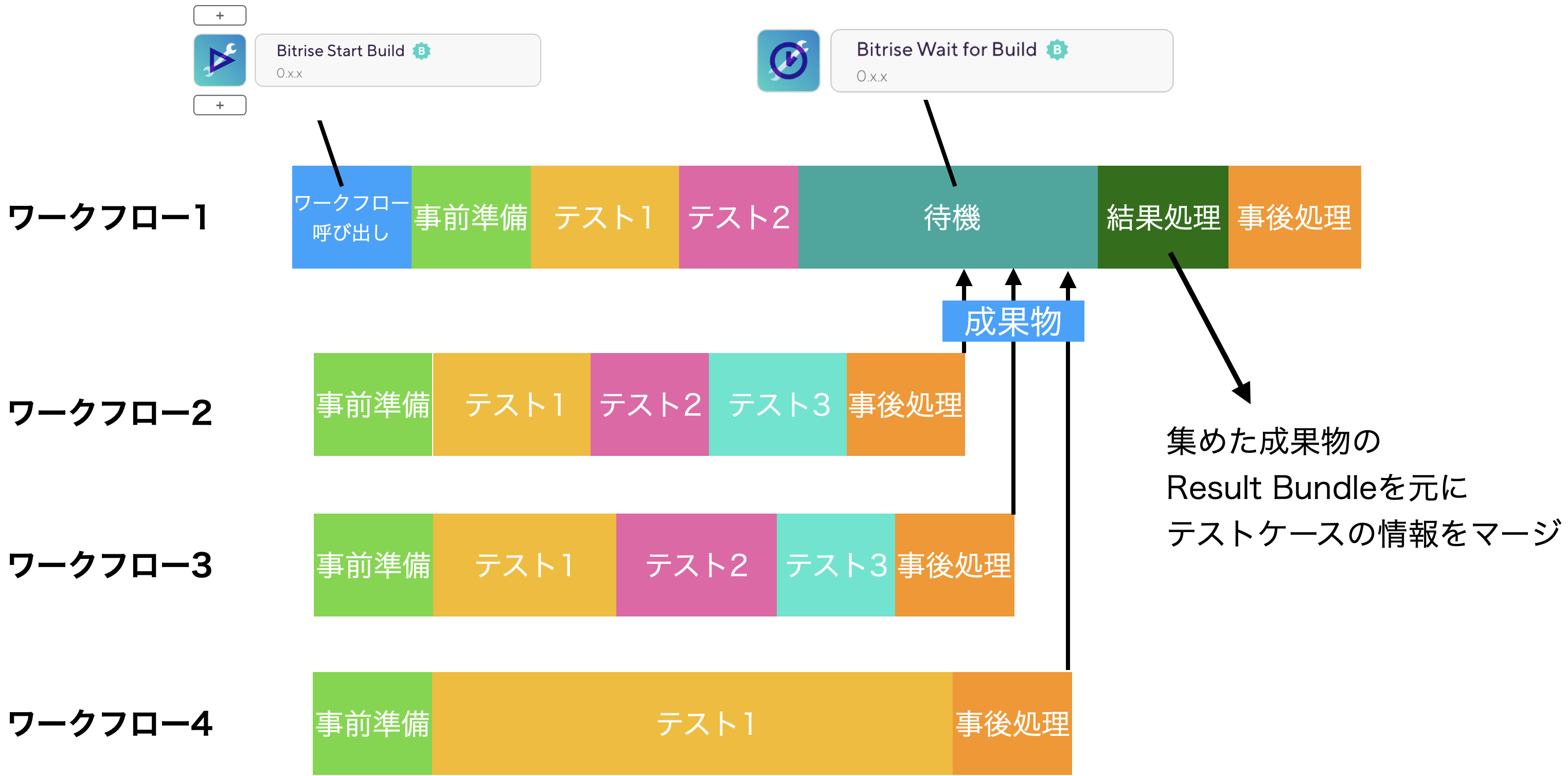
上の図を元に説明をしていきます。 ワークフロー1がメインのワークフローとなります。 ワークフロー2〜4までがワークフロー1きっかけで動く他のワークフローです。
ワークフロー1では「Bitrise Start Build」ステップを利用して他に動かすワークフローを指定します。 また、他のワークフローが動いている間にワークフロー1でもテストを実行します。
そして、ワークフロー1にある「Bitrise Wait for Buildステップ」で他のワークフローが終わるのを待機します。 また、ここで他のワークフローの成果物をまとめてテストケース数などを計算するようにしています。
ステップの実行時間のチェック
上記の並列化は「テスト」においては効果がありますが「ビルド」は並列化できません。 そこで、共通で利用するようなステップがどれぐらい時間がかかっているかをチェックしました。
ここの実行時間が削減できれば、ワークフロー全体に効果があります。
調べた結果として次の3つのステップで多少時間がかかっていました。
- (1)git cloneステップ
- (2)fastlaneステップ
- (3)Cacheステップ
1つ目はgit cloneステップで、Repositoryの肥大化によってcloneをすると2〜3分もかかっている状態でした。
公式のステップはPR時にdepthの設定が解除される作りだったため、独自にステップを作るかこの公式ステップにPRを出すかを検討しましたが、4.0.27バージョン頃から対応されるようになったため、depthを指定するようにしました。
これはgit cloneステップの「Checkout options」にある「Limit fetching to the specified number of commits」で指定できます。 これにより2〜3分かかっていたのが20秒前後にまで削減されました。
2つ目はfastlaneステップです。
fastlaneを使ってビルドやテストをするためのセットアップをおこなうlaneを用意していて、それをBitriseでよんでいました。 Pluginfileに指定してある独自のプラグインも含めgem install時のdependencyが多くインストールに多少時間がかかっている状態でした。
これらはキャッシュに乗せておくことで、その時間は緩和されますがfastlaneはバージョンアップ頻度も多く、ある程度バージョンアップする必要もあります。
しかし、このセットアップ処理自体は別にfastlaneを使わないといけないわけではありませんでした。 そこで、今回はfastlaneを使わない形に変更しました。
最後はCacheステップ(Pull、Push)です。
ビルドを早くするためになんでもCacheしたいという気持ちは出がちですが、Cacheするものが増えてくると、どうしてもCacheのPullとPushに時間がかかってしまいます。
そこで、必要なもののみキャッシュをするようにしました。
また、プロジェクトで利用しているGemfileに記載されていたgemについて整理整頓をおこない使っていないものは全て削除しました。
ビルドマシンのスペックの変更
上述したように色々と実行時間を短縮させるための行為をおこないました。
しかし、最後はある意味「金の弾丸」です。
BitriseはGen2を今年(2021年)から提供しはじめました。 Gen2についての情報については次のブログを参考にしてください。
BitriseがGen2を提供したことにより、利用するビルドマシンのスペックがさらによくなりました。 現在、利用しているGen2のビルドマシン(Elite XL)と今まで利用していたGen1のEliteを比べると次のとおりです。
- Gen1 Elite:4vCPU@3.5GHz、8GB RAM
- Gen2 Elite XL:12vCPU@3.2GHz、54GB RAM
このスペックの変更により、アプリのビルドは40%程度実行時間が削減されました。 また、テストにおいてはビルドほどではありませんがある程度の実行時間が削減されました。
テストの実行時間の短縮結果
これらの対応の結果、どの程度実行時間が短縮したかについて説明します。
直近4週間の結果(Bitrise Insightsより)は次のとおりです。 これは全てのテスト実行(PR時、PUSH時)での結果になります。

以前の結果(41分22秒)と比べて30%ほどになっています。 当初予定していた時間は10分程度ですが、一応達成できたと言えます。
実行時間を削減する案は他にもあるのですが、まずは慣れる場を用意することを優先するためこの時間で一旦はOKとしました。
(3)情報の可視化
Bitriseでいろいろと実行するようになったこともあり、Bitriseの実行履歴から情報を追えます。 しかし、Bitriseの実行履歴を見て情報を追うのはなかなか面倒です。
情報をあとからおいやすくすることで、問題が起きたときに分かりやすくしました。 そこで次のような情報の可視化をおこないました。
- GitHub Commit Statusの利用による可視化
- ビルド結果の可視化
GitHub Commit Statusの活用
デフォルトのBitriseの機能ではCommit Statusに対する情報は成功、失敗といった情報ぐらいです。 そこであとからCommit Statusを見たときにどのような状態だったかが分かるようにしたいというのがありました。
そこでワークフローの種類によって、Commit Statusにそれぞれ結果を反映させるようにしました。
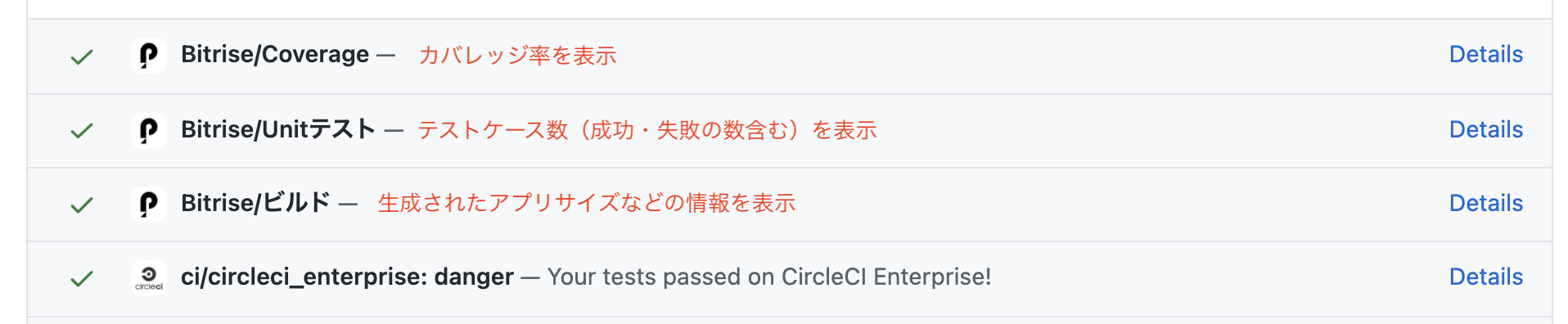
上記の図にあるように単にワークフローの成否だけでなく、テストケース数やカバレッジ率も設定するようにしています。 これにより、例えばある時点から特定のワークフローが失敗しているとか、そのときに特定のテストケースが失敗しているのか、Compile Errorなのかといったことまで分かるようになっています。
情報の可視化
Bitriseで実行したワークフローの結果を、SWETメンバーが開発し導入しているCIAnalyzerを利用して下図のように可視化をおこなっています。
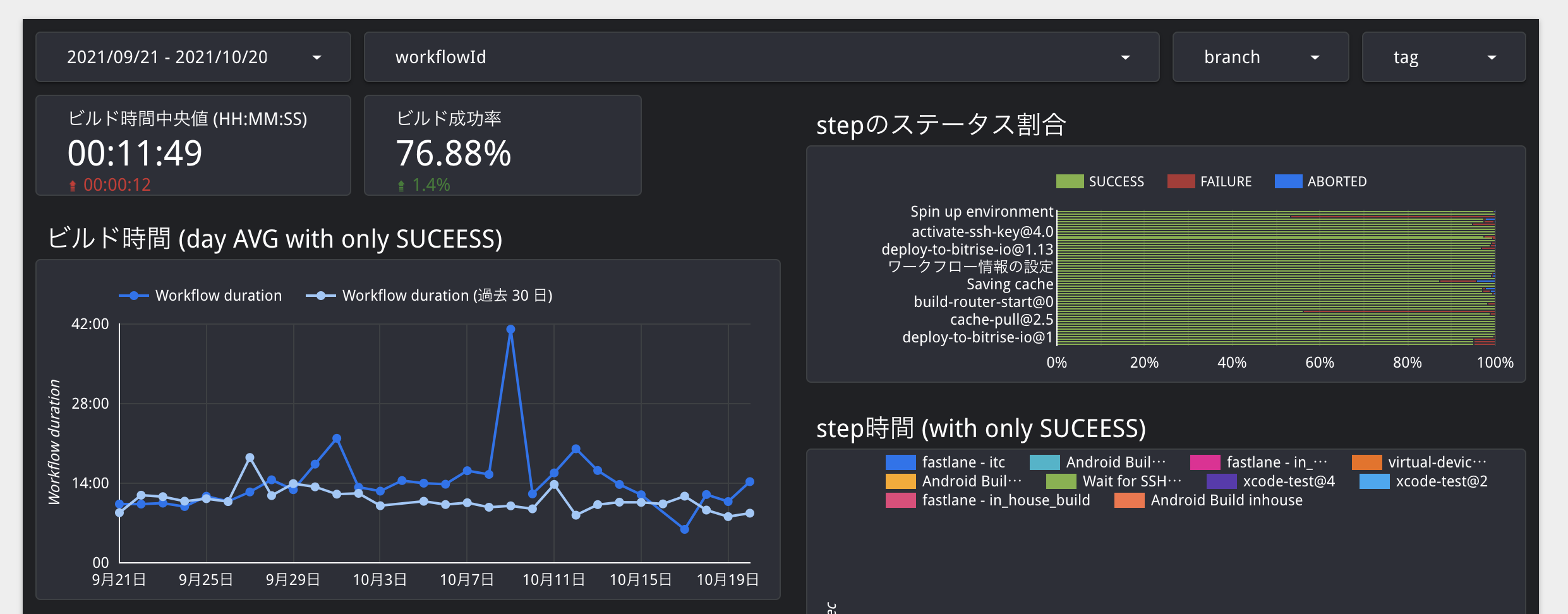
これにより、ビルドの状態(ワークフローやステップ単位での実行時間やビルドの成功率など)を後からでも簡単に確認できるようになりました。 ただし、この手の可視化をおこなったとしても見てくれるとは限りません。
そこで、定期的に関係者に状況をシェアするようにしていました。 例えば「xx月と比べてテストの実行時間がyy%削減されました」とか「最近xxというワークフローの実行時間が少しずつ上昇しているようです」などです。
また、すでに紹介していますがBitriseでもInsightsという機能を提供しています。 この機能でも同様に履歴がわかるようになっていますし、ステップ単位での実行時間も分かります。 最近リリースしたばかりで、どのプランでも30日間の無料アクセスを提供しているとのことなので、1度見てみると良いと思います。
(4)安定運用するための対応
CI/CDを安定的に運用するためには上記の対応も重要なことです。
しかし、実行時間が短くなってPRのたびに動いたとしても、ビルドが失敗した場合に対応をせずに放置してしまうという状態はよくありません。
失敗した際に放置してしまう理由はいくつかあります。
- 失敗していることに気づいていない
- 単にSlackの通知チャンネルに通知しているだけでは通知数の多さでスルーされてしまうことはあります
- 失敗した原因の対応コストが高い
- 上述したとおり環境起因で落ちる場合は対応コストがどうしてもある程度かかってしまいます
そこで安定運用するためにおこなったことについて次に説明をしていきます。
期間限定の門番
最初に述べた「Step2」の対応が出来ない間(システム的に守れない間)の一定期間はBitriseに対する門番となりました。
門番としておこなったこととしては、おもに次のとおりです。
- ワークフローが失敗したときの初期調査
- Bitrise周り全般の相談窓口
失敗したときの初期調査においては、より失敗を見つけやすいようにSlackの通知周りの整理整頓もおこないました。 これについては後述します。
失敗を見つけたらBitriseのログを調査し、原因を追求した上で「対応をおこなう」「対応方法を伝える」のどちらかを行いました。
これを繰り返しおこないつつ、少しずつ自分で対応をするという範囲を狭めていきました。
失敗を知ってもらい対応してもらうための工夫
失敗した場合に、それに気づいてもらう必要があります。 そこで、何かしら問題が起きたときにすぐに気づけるような状態にしておきます。
- Slack通知の整理整頓
- 失敗時におけるSlack通知先の変更
Slack通知は多くなりがちです。 通知する箇所の整理や通知内容について整理整頓をおこないました。 表示する内容も変更し、テスト結果や実行時間なども表示するようにしました。
次に失敗時におけるSlackでのメンションです。 当初は失敗した場合にSlackのユーザーグループにメンションをするというのもおこないましたが、PR単位も含めると失敗することはよくあることです。
結果、メンションをしすぎてしまい逆に放置されてしまう原因になってしまいます。
そこで、ワークフローが失敗してはいけないような「デフォルトブランチ」や「リリースブランチ」においてだけ、失敗した時点で開発メンバーがメインで利用しているチャンネルにSlack通知をするようにしました。
これで、問題に気づきやすくなりました。
最終的には問題が起こらないようにする必要があります。 通知をおこなうのではなく、そもそも「失敗したものがマージされないようにする」のが望ましいです。 しかし、この段階でその設定までおこなうのはまだ時期尚早なため、まずは知ってもらうというのを優先しました。
おこなった結果
行いたかった「Step1」と「Step2」は次のとおりです。
- Step1:PR時点で「ビルド」「テスト」のワークフローを動かす
- Step2:「ビルド」「テスト」のワークフローが失敗したものはマージできないようにする
これらがどうなったかについて次に説明していきます。
Step1に対する結果
実行時間の短縮により「課題1」は解決しました。 そこで、PRに対してもワークフローを実行するようにしました。
ただし、一度に「ビルド」と「テスト」を設定するのではなく、まずは「ビルド」を動くようにしました。 PR時に「ビルド」を動かすようになってある程度たってから、追加で「テスト」についても動くように設定しました。
Step2の対応と結果
「Step1」が達成した段階時点では、まだ「Step2」はそこまで必要と認識されていない状況でした。 ある程度、今の状態が慣れるのを待ちつつタイミングを待つこととしました。
ブランチに失敗したままのコードがマージされるケースは、この時点でもたまに起きていました。 それでも、まだStep2についてはおこなえていない状態でした。
しかし、実際に検証前にビルドができないといったような「誰もがこの状態は良くない」と思える事件が発生した時点で、今後の予防として「Branch Protection Rule」の導入を提案しました*2。
この時点ではPR時に「ビルド」「テスト」が動くようになってからある程度たっている状態でした。 これらのワークフローの実行時間があまりかかってないことを共有し、導入することになりました。
Branch Protection Ruleの導入
一度に導入するとなにかあったときの対応コストは多くなります。 その結果として導入をやめようという流れにもなりかねないため、少しずつ設定を追加するようにしました。
まずは次の設定を入れました。
- PRの向き先のブランチ:「リリースブランチ」
- 「Require status checks to pass before merging」をオン
- ビルドを必須
- GitHub Commit Statusをそれぞれ独自におこなっているので設定はかんたん
- ビルドを必須
- 「Require status checks to pass before merging」をオン
設定を入れた状態にし、なにかしら問題が起きたら即時対応をするようにしました。 例えば、Bitrise起因でビルドが出来ないなどの対応があります。
上記の設定を導入し、ある程度たったのちに次のように拡大をしていきました。
- PRの向き先のブランチを拡大:「リリースブランチ」「デフォルトブランチ」
- 「Require status checks to pass before merging」
- ビルドを必須
- テストを必須
- 「Require status checks to pass before merging」
この設定を入れて、慣れてくるようになるとエンジニアメンバーからも提案が出てくるようになりました。 そこで、次の設定を入れることにしました。
- Require pull request reviews before merging
- レビュー必須(approve 1件以上)
これにより「ビルド」「テスト」ができないもの、コードレビューがされていないものは基本マージができなくなり、事故が起こることは減りました。
これで当初予定していた「Step1」と「Step2」のそれぞれの対応が終わりました。
おわりに
求める姿を想定し、そこに進めていくのは必ずしも一直線とは限りません。
その状態自体が本当に自分たちにとって良いのかも分からないこともしばしばありますし、その状態にすることによる大変さがあるかもしれないと思うかもしれません。
今回は、上述したように少しずつ対応を進めていきました。 そして、少しずつメンバーに慣れていってもらうようにしました。
その結果として、当初予定していた「求める姿」になりました。
この状態がベストではなくまだ先の「求める姿」があると思っています。 また、プロジェクトの状態が変わっていけばまた変えるべき箇所も出てくるとは思います。
今後も現在の状況を見ながら、「求める姿」を考えて対応を進めていければと思います。
最後に、上記のような活動に興味を持ってくれた方、一緒に働いてみたいなと思ってくれた方。 現在、SWETはメンバーを募集中ですのでぜひ応募ください。