1. はじめに
SWETグループの井口です(@hisa9chi)です。現在はスマホ向けゲーム開発案件にてゲーム開発者がゲーム開発に集中できるようにCI/CD関連を幅広くサポートしています。 本稿では、その中でも Jenkins Pipeline Job で利用可能な Shared Libraries に関して弊社でどのように活用しているか事例を紹介してみたいと思います。
Jenkinsと聞くとおそらく皆さんは、昔は利用していたが今は運用コストが高いなどの理由から、マネージドなクラウドのCI/CDサービスへ移行したという方が多いのではないでしょうか。しかし、ゲーム開発の現場ではJenkins master / agentのクラスタ構成を構築して、運用を続けているプロジェクトが弊社内にも多く存在します。なぜ、運用コストが高いにもかかわらず構築して運用しているかというと、ゲーム開発特有の理由からです。
ゲーム開発において、修正後にビルドして実機で動作やレイアウトなどを確認するサイクルはとても重要です。このサイクルが短ければ短いほどゲームの修正確認がスムーズに行え、ゲーム開発者はゲーム開発に集中できると思います。しかし、ゲーム開発では大容量のデータを扱うことが多く、開発が進むにつれてビルド時間が増加する傾向にあります。そのため、ビルド時間を少しでも短くするために、高スペックな物理マシンを手元に用意してJenkins master / agentのクラスタ構成を構築して運用しています。
この運用コストに関しては本稿では触れませんが、SWETとして取り組んでいることをCEDEC 2020にて発表しております。発表資料は以下にありますので、そちらも参考にしていただければ幸いです。
CEDEC 2020「モバイルゲーム開発におけるJenkinsクラウド時代のJenkins構築と管理テクニック」
2. 前提
本稿では以下を前提としております。
- Jenkins masterのversionは2.x系
- 実際の動作を確認したのは ver.2.222.3
- Jenkins Pipeline JobはDeclarative Pipeline
- Scripted Pipelineではないので注意
3. Jenkins Shared Libraries
3.1. 概要
Jenkinsのジョブ作成にてPipeline Jobが多く利用されるようになると、共通処理が複数のPipeline Jobで出現することがあります。この共通処理をPipeline Jobとは切り離して定義できれば、Pipeline Jobのメンテナンス性向上や共通処理等の再利用性も向上します。この共通処理等をPipeline Jobの外部に定義して、Pipeline Jobごとにロードして利用する仕組みが、Shared Librariesです。
3.2. 特徴
Shared Librariesの特徴として以下があります。
ジョブ毎に異なるバージョンの利用が可能
ライブラリをSCM管理しているため、ブランチ/タグ/コミットハッシュ指定でジョブごとに異なるバージョンのライブラリをロードして利用可能です。メンテナンス性と再利用性の向上
共通処理等をPipeline Jobの外に定義しているため、変更はライブラリ内に閉じることが可能です。また、Jenkins masterが異なる場合でも、ライブラリが管理されているリポジトリへアクセス可能であれば容易に利用可能です。他にも、Pluginの利用をラップしたライブラリを作成しておくことで、Pluginの更新に伴う変更もライブラリ内に閉じることが可能な場合もあります。classメソッドのapproveが不要
Pipeline Job内でgroovyを用いてclassメソッド1を利用した処理を定義していた場合、そのclassメソッド毎にapproveが必要となる場合があります。Jenksinfile内のgroovyコードで多くのclassメソッドを利用していてapproveされていない場合、このapprove作業は非常に面倒な作業となります。しかし、Shared Librariesであればapproveする必要がないためそのような面倒な作業は発生しません。
3.3. 作成
基本的にはライブラリ群を決められたディレクトリ構造で作成して、そのリポジトリをSCM管理します。そのリポジトリをJenkins側に設定してジョブごとでライブラリを読み込むように設定することで、ジョブごとのワークスペースにライブラリ群がチェックアウトされて利用可能になります。
先に示した公式のドキュメントに詳細は記載されていますが、簡潔に説明するとディレクトリ構造として大きく以下となります。
- src
- パッケージに分けて独自のクラスを定義可能
- var
- pipeline jobで利用可能な変数定義(.groovy)とヘルプファイル(.txt)
- xxx.groovyのファイル名を変数として利用可能でありそのファイル内に定義されているメソッドを {ファイル名}.{メソッド名} で呼び出し可能
- resources
- groovyではないファイル(xxx.jsonやxxx.sh等)を格納
- libraryResourceを利用してメソッド内で利用が可能
src/var/resourcesに関しての実装サンプルは公式のサンプルがわかりやすいのでそちらを確認してください。
3.4. 利用
作成したShared Librariesを利用する場合は以下の2ヵ所に設定が必要となります。
- Jenkinsのシステム設定
- ジョブごとにライブラリをインポート
3.4.1. Jenkinsのシステム設定
Pipeline Jobにてロード可能なライブラリをGlobal Pipeline Librariesへ設定します。JenkinsからSCM経由でライブラリにアクセス可能であることが前提となります。
設定箇所は以下のように 「Jenkinsの管理」-「システムの設定」内の Global Pipeline Libraries の項目になります。
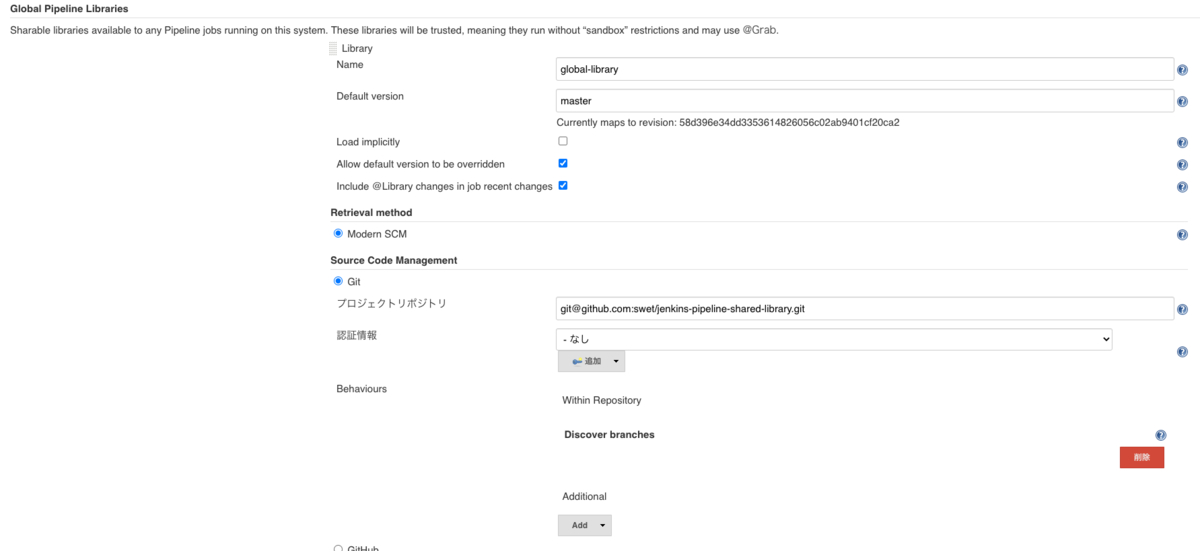
| 項目 | 設定内容 | 設定例 |
|---|---|---|
| Name | ライブラリ名。ジョブでインポートする際に利用 | mylibrary |
| Default version | ブランチ名、タグやコミットハッシュを指定 | master |
| Retrieval method | 利用するSCM | Modern SCM |
| Source Code Management | 利用するSCMサービス | Git |
| プロジェクトリポジトリ | リポジトリURL | SSH or HTTPSアクセス用URL |
| 認証情報 | リポジトリへの認証情報 | credentialsに登録済みの物を指定 |
3.4.2. ジョブごとにライブラリをインポート
基本的には、Pipeline Job内で @Library を活用して先ほど設定したライブラリを読み込みます。
// ライブラリの読み込み // デフォルトバージョンの読み込み // "Global Pipeline Libraries 設定" の "Default version" @Library( 'ライブラリ名' ) _ // ブランチやタグを指定する場合 @Library( 'ライブラリ名@{branch名 | tag名}' ) _ // 複数ライブラリの読み込み @Library( ['ライブラリ名1', 'ライブラリ名2'] ) _
注意が必要なのは最後の _ を忘れないことです。これがなければエラーとなるので注意してください。 _ を記載することでライブラリ側に定義した、var 配下のスクリプトが利用可能になます。利用には var 配下のファイル名をそのまま変数名として利用できます。
また、src などで独自に定義したclassの利用に関してはそのクラスをimportする必要があります。
// srcで定義した class を利用する場合 // 利用したい class を import する必要あり @Library( 'ライブラリ名' ) import org.foo.Sample // 利用時は script { } ブロック内で利用する script { def sample = new org.foo.Sample() sample.hello() // Sample 内に定義されている hello() メソッドの呼び出し }
srcで定義されているclassを利用する場合は script {} ブロックに入れる必要があることに注意してください。
4. 活用事例
では、実際に弊社でどのように利用しているか実際の以下の3つの事例を紹介させていただきます。
- 成果物等のGCSアップロード
- ジョブ終了時に自動メンション(Slack通知)
- ジョブ失敗時のstage名の取得
4.1. 成果物等のGCSアップロード
ジョブを実行した際の成果物やログなどはarchiveArtifacts Pluginを活用してJenkins masterに保存しておくことが一般的かと思います。しかし、ジョブの成果物はサイズが大きい物などもありJenkins masterのディスク容量を圧迫してしまいます。この対策として、ジョブごとにビルド履歴の保存件数を制限するbuildDiscarderを設定する方法があります。ただし、以下の問題があります。
- ジョブ数が多い場合は結果ディスクフルになってしまいジョブが正しく動作しない
- ビルド履歴を制限すると過去の成果物の取得ができない
これらを解決する施策として、クラウドのストレージであるGCSやS3にアップロードして保存しておくことが挙げられます。今回はGCSへのアップロードを例にShared Libraryの利用事例をご紹介します。
GCSへのアップロードにはGoogle Cloud Storage Pluginを利用することで簡単に行えます。ただ、アップロードの際には対象のバケット配下に {ジョブ名}/{ビルド番号} のディレクトリを作成してアップロードしたいという要望があります。Pluginをそのまま活用するとアップロード先にバケット名だけでなく {バケット名}/{ジョブ名}/{ビルド番号} とジョブ毎に指定する必要があります。バケット名に関してはジョブ毎に変更する可能性はありますが、ジョブ名やビルド番号は共通してJenkinsの環境変数から取得して指定します。この共通部分をジョブごとに記載するのは煩わしいためライブラリ化しています。
// var/gUploadArtifactsToGCS.groovy #!/usr/bin/env groovy // Google Cloud Storage Uplaod(for Google Cloud Storage Plugin) def call( Map params = [:] ) { // 必須パラメータチェック if ( params.bucket == null ) { println "gUploadArtifactsToGCS: 'bucket' param is not specified." return } if ( params.credentialsId == null ) { println "gUploadArtifactsToGCS: 'credentialsId' param is not specified." return } if ( params.pattern == null ) { println "gUploadArtifactsToGCS: 'pattern' param is not specified." return } def uploadDir = "gs://${params.bucket}/${env.JOB_NAME}/${env.BUILD_NUMBER}" // Google Cloud Storage Plugin の提供メソッド googleStorageUpload( bucket: uploadDir, credentialsId: params.credentialsId, pattern: params.pattern ) }
// Jenkinsfile @Library( 'mylibrary' ) _ pipeline { agent { label 'master' } stages { stage ( 'sample' ) { steps { sh 'touch sample.txt' gUploadArtifactsToGCS( bucket: ARTIFACTS_BUCKET_NAME, credentialsId: GCS_CREDENTIAL_ID, pattern: 'sample.txt' ) } } } }
上記のようにShared Libraryを呼び出すことで指定したバケット ARTIFACTS_BUCKET_NAME 配下に {ジョブ名}/{ビルド番号}/sample.txt としてアップロードされます。
他にも以下のような情報をGCSへアップロードするようなライブラリを作成して利用しています。
ジョブ実行時に指定したビルドパラメータとビルドログ
Jenkinsにて定義済みのclassを活用してファイルに出力してGCSへアップロードジョブを実行したビルドマシンの環境情報
agentのOSやツールのバージョンを取得するスクリプトをShared Library側に登録してそれを呼び出して情報を収集してGCSへアップロード
4.2. ジョブ終了時に自動メンション(Slack通知)
ジョブが終了した際に結果をSlackなどへ通知していることは多いかと思います。弊社でもJenkinsのジョブを手動でトリガーした場合やcronで実行された際の結果をSlackへ通知(Slack Notification Pluginを利用しています)しています。しかし、ジョブも多く頻繁に実行されると通知の数が増えるため、Slackの通知が埋もれてしまい気づけない状況が発生するため、特定の人へメンションしたいというケースがあります。
あるプロジェクトでは、ジョブ毎にメンション先をビルドパラメータ化して実行時に設定してもらうという運用がなされていました。しかし、この方法は利用側からすると面倒であり指定を間違えてしまうこともあります。そのため、ジョブをトリガーしたユーザの情報から自動でそのユーザにメンション付きでSlack通知するようにライブラリを作成して利用しています。
仕組みを簡単に説明すると、トリガーしたユーザのメールアドレス(Slackに登録しているアドレスと同一)を元に、SlackのIDを検索してそのユーザへメンションするための文字列である <@UserID> を返却しています。2
// var/gGetSlackUsersMentionString.groovy import java.util.concurrent.TimeUnit import groovy.json.* @Grab( group='com.squareup.okhttp', module='okhttp', version='2.7.5' ) import com.squareup.okhttp.OkHttpClient; import com.squareup.okhttp.Request; import com.squareup.okhttp.RequestBody; import com.squareup.okhttp.Response; def call( Map params = [:] ) { // 必須パラメータチェック if ( params.userEmails == null ) { println "gGetSlackUsersMentionString: 'userEmails' param is not specified." return } // 必須パラメータチェック if ( params.slackAPIToken == null ) { println "gGetSlackUsersMentionString: 'slackAPIToken' param is not specified." return } String slackApiUrl = 'https://slack.com/api/' String apiMethod = 'users.list' String query = 'token=' + params.slackAPIToken; String requestUrl = slackApiUrl + apiMethod + '?' + query Request request = new Request.Builder() .url( requestUrl ) .header( 'User-Agent', 'jenkins' ) .get() .build(); OkHttpClient client = new OkHttpClient(); client.setConnectTimeout( 5, TimeUnit.MINUTES ); // connect timeout client.setReadTimeout( 5, TimeUnit.MINUTES ); // socket timeout // Response Response response = client.newCall( request ).execute(); // json へ変換 Object json = new JsonSlurper().parseText( response.body().string() ) // User の mention 用 ID 文字列 String mentionIdsStr = ''; // email から User ID を検出 for ( user in json.members ) { for ( target in params.userEmails ) { if ( user.profile.email == target ) { mentionIdsStr += '<@' + user.id + '> ' } } } return mentionIdsStr; }
// Jenkinsfile @Library( 'mylibrary' ) _ pipeline { agent { label 'master' } stages { stage ( 'sample' ) { steps { script { def mentionStr = gGetSlackUsersMentionString( userEmails: [ EMAIL_ADDRESS ], slackAPIToken: SLACK_API_TOKEN ) // Slack Notification Plugin の提供メソッド slackSend( color: 'good', message: "${mentionStr}\n Message from Jenkins Pipeline" ) } } } } }
上記のように利用することで、ジョブをトリガーしたユーザへのメンション付きでSlack通知することを可能にしています。
4.3. ジョブ失敗時のstage名の取得
こちらもSlackに通知する際の便利機能の1つになります。Jenkins Pipeline Jobでは複数のstageが定義されています。ジョブが失敗した際のSlack通知にて、どのstageで失敗したかも補足情報として通知されているとエラー箇所の確認などに役立ちます。しかし、エラーとなったstageを特定するのは以下のように面倒であり、Jenkinsfileへのコード量も増えてしまいます。
// Jenkinsfile pipeline { agent { label 'master' } stages { stage( 'sample' ) { .... } post { // 失敗となった場合に stage 名称を環境変数に設定 failure { script { env.ERROR_STAGE='sample' } } // ここまでがエラー stage 名称の設定 } } // Declarative: Post Actions post { failure { // Slack Notification Plugin の提供メソッド slackSend( color: 'danger', message: "ErrorStage: ${env.ERROR_STAGE}" ) } } }
上記のように全てのstageの post { failure { script {} } } ブロックにて env.ERROR_STAGE='ステージ名' というような設定を記載する必要があります。これはかなり面倒であり、多くのメンバーでメンテナンスをしていると記載を忘れてしまうこともあります。
そのため、最後の Declarative: Post Actions でfailureの際にエラーとなったstageを取得できれば余計なコードもなくなりスマートになります。Pipeline Jobの環境変数などでエラーstage情報が提供されていないため、Jenkinsのクラスからstageを取得する以下のライブラリを作成して利用しています。
// vars/gGetFailedStageName.groovy #!/usr/bin/env groovy import hudson.model.Run; import org.jenkinsci.plugins.workflow.job.WorkflowRun; import org.jenkinsci.plugins.workflow.graphanalysis.ForkScanner; import org.jenkinsci.plugins.workflow.pipelinegraphanalysis.StageChunkFinder; import com.cloudbees.workflow.rest.external.StageNodeExt; import com.cloudbees.workflow.rest.external.StatusExt; import com.cloudbees.workflow.rest.external.ChunkVisitor; def call() { String errorStageName = ''; WorkflowRun workFlowRun = currentBuild.getRawBuild(); ChunkVisitor visitor = new ChunkVisitor( workFlowRun ); // stage 情報の取得 ForkScanner.visitSimpleChunks( workFlowRun.getExecution().getCurrentHeads(), visitor, new StageChunkFinder() ); // 全ての Stage のステータスを検索 for ( StageNodeExt stageExt : visitor.getStages() ) { if ( stageExt.getStatus() == StatusExt.FAILED ) { errorStageName = stageExt.getName(); break; } } return errorStageName; }
// Jenkinsfile @Library( 'mylibrary' ) _ pipeline { agent { label 'master' } stages { stage ( 'sample' ) { .... error '強制的にエラー' // 以降の stage はスキップ stage のステータスはエラー状態 } } // Declarative: Post Actions post { failure { // Slack Notification Plugin の提供メソッド slackSend( color: 'danger', message: "ErrorStage: ${gGetFailedStageName()}" ) } } }
上記のように利用することでエラーとなったstage名をSlackのメッセージ内に入れることが可能になります。

ただし、先頭から確認して最初にエラーとなったstage名のみ(上記のサンプルでは "sample" stage名のみ)を返却するようになっています。基本的には最初にエラーとなったstage以降のstageはスキップされ失敗した状態となっています。そのため、最初にエラーとなったstage名だけを返却する方針で良いと判断したためこのような仕組みとなっております。
5. 終わりに
今回は弊社で利用しているJenkins Piepline JobにおけるShared Librariesの利用事例を紹介しました。今回紹介したのは一部であり、Shared Librariesは独自クラスを定義してJenkins Pipeline Jobで利用が可能になるなど他にも多くの利用方法が挙げられます。Shared Librariesに関しては私たちも日々どのように利用するのが良いか色々と模索しています。ですので、自分たちも利用しているという方がおられましたら、これを機会にどのように活用しているかなどのノウハウや情報をお互いに交換できればと思っています。 もし、ざっくばらんに話してみたいなどありましたら井口(@hisa9chi)までご連絡いただければと思います。
-
例えばユーザID情報を取得のメソッドである
hudson.model.Cause$UserIdCause getUserId()など↩ -
Shared Libraryを使ってSlackのUserIDを取得していますが、現在ではPluginでemailからSlackのUserIdを検索できるようになっています。slackUserIdFromEmail↩