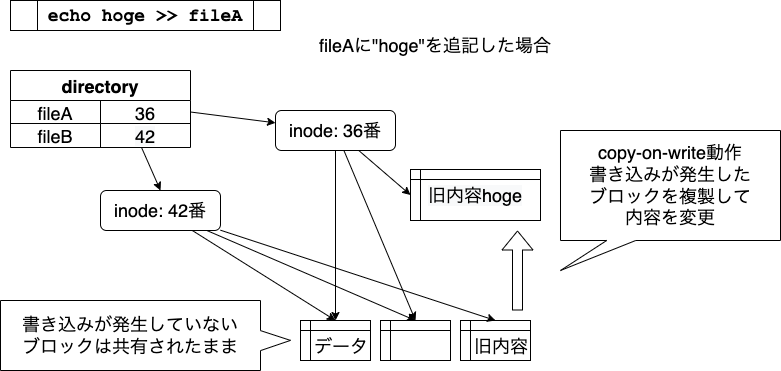
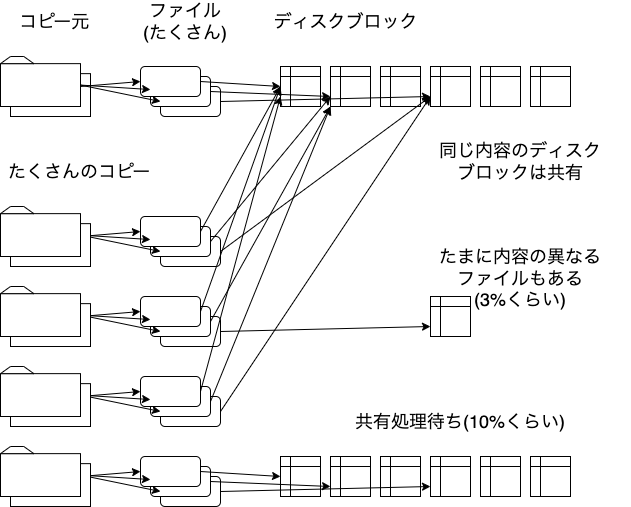
こんにちは。SWETのAndroidチームに所属している外山(@sumio_tym)です。 SWET AndroidチームではAndroidのプロダクトに対して自動テストのサポートをしています。
はじめに
先日開催されたDroidKaigi 2022で「Gradle Managed Virtual Devicesで変化するエミュレータ活用術」というタイトルで登壇しました。
本セッションの動画もYouTubeのDroidKaigiチャンネルに公開されていますので、合わせて参考にしてください。
さて、本記事では、上記セッションの内容から開発PC上でGradle Managed Devices (GMD)を試すのに必要な部分だけを抜粋して紹介していきます。 本記事を読むだけで手っ取り早くGMDを試せるように構成してありますので参考にしてみてください。
Gradle Managed Devices (GMD)とは
Gradle Managed Device(GMD)とは、Gradle Managed Virtual Devicesとも呼ばれる機能で、Android Gradle Plugin 7.3より本格的に導入されました。
本機能を使うと、build.gradleに使いたいエミュレータの情報を書くだけで、Gradleタスクひとつ(コマンドひとつ)で次の一連の工程を実行できるようになります。
build.gradleで指定されたエミュレータ種別に合うAVD(Android Virtual Device)を作成する
(すでにあれば再利用する)- 作成したAVDでエミュレータを起動する
- 起動したエミュレータ上でテスト(Instrumented Test)を実行する
- テスト実行が終わったら、インストールしたアプリ(apk)を削除する
- 起動したエミュレータを終了する
- テスト結果レポートや実行ログを保存する
build.gradleの記載内容だけでテストを実行するエミュレータの環境が定まり、コマンドひとつで実行できることから、次のようなメリットが得られます。
- 開発者が手動で(Android Studioを操作して)AVDを作成しなくてよい
- テスト実行時におけるエミュレータの環境差異をなくせる
- エミュレータを使ったテストのCI上での実行が簡単にできる
GMDのセットアップとタスクの実行
GMDを使うための手順は次のような流れになります。順を追って説明します。
- 利用するAGP(Android Gradle Plugin)のバージョンをGMD対応版にする
build.gradleにテストを実行したいAVD(エミュレータの種別など)を定義する- GMD上でテストを走らせるGradleタスクを実行する
Android Gradle Pluginのバージョン指定
前述のとおり、GMDに本格対応したバージョン7.3.0以降を使うようにしてください(本原稿執筆時点では7.3.1が最新の安定バージョンです)。
buildscript {
...
dependencies {
classpath "com.android.tools.build:gradle:7.3.1"
...
}
}
テストを実行したいAVDの定義
モジュールレベルのbuild.gradle(app/build.gradleなど)に次の形式で定義します。
android {
testOptions {
managedDevices {
devices {
pixel5api33 (ManagedVirtualDevice) { //・・・(1)
device = "Pixel 5" //・・・(2)
apiLevel = 33 //・・・(3)
systemImageSource = "google" //・・・(4)
require64Bit = false //・・・(5)
}
}
}
}
}
それぞれの指定の意味は次のとおりです
(番号は上記ビルド定義ファイル中のコメントと対応しています)
- (1)
pixel5api33: デバイス(AVD)を一意に識別する名前を指定します。適当な名前を付けてください - (2)
device: Device Profileを指定します。 Android StudioのDevice Manager>Create deviceで表示されるデバイス名から選択してください - (3)
apiLevel: 起動したいエミュレータのAPI Levelを指定します - (4)
systemImageSource: 利用するシステムイメージの種別を指定します。後述します - (5)
require64Bit: 64ビットのABIを強制的に使うか否かを指定します。通常はfalseで問題ありません
systemImageSourceで指定できるシステムイメージの種別は次のとおりです。
| 従前のシステムイメージ | ATD | |
|---|---|---|
| 無印(AOSP) | aosp |
aosp-atd |
| Google APIs | google |
google-atd |
| Google Play | google_apis_playstore |
N/A |
表の右カラムに記載されているATD(Automated Test Device)は、Instrumented Test用途に最適化された軽量版のシステムイメージで、本原稿執筆時点ではAPI Level 30と31で利用可能です。 ATDではハードウェアレンダリングが無効化され、さらにテストで使わなさそうなアプリやサービスが削除・無効化されています。 削除・無効化されている機能の一覧は公式ドキュメントを参照してください。これらの機能なしでテストが動きそうであればATDを試してみるのもよいと思います。
Gradleタスクの実行
GMD上でテストを走らせるGradleタスクは次の形式になっています
{デバイス名}{ビルドバリアント}AndroidTest
たとえば、デバイス名pixel5api33に対して、debugビルドバリアント(フレーバー未定義でビルドタイプがdebugの場合)のテストを走らせたい場合は、次のコマンドでテストを実行できます。
./gradlew pixel5api33DebugAndroidTest
テストの結果レポートやログは次のディレクトリに保存されます。
app/build/outputs/androidTest-results/managedDevice/flavors/{フレーバー名}/{デバイス名}/- JUnit互換のテスト結果XML
- ログ(logcatや、AGPが内部で実行したadbなどのコマンドログ)
app/build/reports/androidTests/managedDevice/flavors/{フレーバー名}/{デバイス名}/- HTML形式のテスト結果レポート
知っておくと便利なテクニック
GMDは、コマンド1つでエミュレータ上でのテストの実行を完結してくれる反面、運用上使いにくいと感じる場面もあります。 たとえば、次のような場面です。
- テスト実行中の画面が見えない
- テストが終わるとapkがアンインストールされてしまうため、テスト実行中に作られたファイルも消えてしまう
- Android Studioでじっくりデバッグできない
これらの問題解決の助けになるテクニックを3つ紹介します。 この3つのテクニックを知っておくと、GMDを試すときの動作確認が格段にやりやすくなります。是非お試しください。
テスト実行中に画面を表示する--enable-display
GMDによるテスト実行タスクに--enable-displayオプションを付けると、テスト実行中にエミュレータの画面が表示されます。
テスト失敗時に画面の状態を目視したいときなどに便利です。
./gradlew pixel5api33DebugAndroidTest --enable-display
なお、軽量版システムイメージであるATDでは、本オプションを付けても真っ黒な画面しか表示されません。ご注意ください。
テスト終了時にファイルをpullするadditionalTestOutputDir
Test Instrumentation Runnerに渡せるadditionalTestOutputDir引数にディレクトリを指定すると、
テスト終了時にそのディレクトリ内のファイルをpullさせることができます。
android {
defaultConfig {
testInstrumentationRunnerArgument(
"additionalTestOutputDir",
"/sdcard/Android/media/com.example.gmd/result"
)
}
}
テストが終了するときに、この例ではエミュレータのディレクトリ/sdcard/Android/media/com.example.gmd/result内のファイルを開発PCに取り出します。
取り出されたファイルはapp/build/outputs/managed_device_android_test_additional_output(AGPのバージョン8.0以上ではapp/build/intermediates/managed_device_android_test_additional_output)ディレクトリに保存されます。
テスト実行中に保存したスクリーンショットファイルやログファイルを取り出したいときなどに便利です。
なお、Scoped Storageが有効なOSのバージョンでは、本オプションに指定できるディレクトリのパスに制限があります。
/sdcard/Android/media/{アプリケーションID}/のような、アプリから書き込めて、かつadb pullできるディレクトリを指定するようにしてください。
その条件を満たさないパスに保存したファイルは本オプションを指定しても取り出せません。
GMDで使われるAVDでエミュレータを起動できるANDROID_AVD_HOME環境変数
GMDによるテストで使われるAVD(Android Virtual Device)は隠されており、Android StudioのDevice Managerからは確認できません。 そのため、GMDで使われるのと同じAVDのエミュレータに対してAndroid Studioからテストするには、コマンドラインを使って事前に対象のエミュレータを起動しておく必要があります。
これから説明する方法でエミュレータの起動さえできてしまえば、普段どおりAndroid Studioからアプリのインストール・デバッグ実行・テストの実行などが行えます。 この方法でテストが十分安定して動くことを確認してから、最終確認としてGMDでテストを実行するようにすると、あまり手戻りすることなくテストを書き進められます。
GMDで使われるAVDが表示されない理由は、デフォルトの場所($HOME/.android/avd)にAVDが保存されていないからです。
Android Gradle Plugin 7.3以上であれば、GMDで使われるAVDは次のディレクトリに保存されています。
$HOME/.android/avd/gradle-managed
このディレクトリを環境変数ANDROID_AVD_HOMEに指定してemulatorコマンドを実行すると、GMDで使われるAVDのエミュレータを起動できます。
まず目的のAVD名を特定するところから始めます。
GMDで使われているAVDの一覧を表示するには次のコマンドを実行してください。
emulatorコマンドは($ANDROID_HOME/toolsではなく)$ANDROID_HOME/emulatorディレクトリにあるものを使ってください。
env ANDROID_AVD_HOME=$HOME/.android/avd/gradle-managed $ANDROID_HOME/emulator/emulator -list-avds
dev33_google_x86_64_Pixel_5 のような、APIレベル・システムイメージ・ABI・Device Profileを組み合わせたAVD名の一覧が表示されますので、目的のAVDをみつけてください。
目的のAVDをみつけたら、次のコマンドでエミュレータを起動できます。
env ANDROID_AVD_HOME=$HOME/.android/avd/gradle-managed $ANDROID_HOME/emulator/emulator -avd {AVDの名前}
直前にGMDでテストを実行している場合は別の手段を取ることもできます。GMDの実行ログを活用する方法です。 エミュレータを起動したときの実行ログは次のファイルに保存されています。
app/build/outputs/androidTest-results/managedDevice/flavors/{フレーバー名}/{デバイス名}/emulator.1.ok.txt
このファイルを開くと次のような内容になっているはずです。
EXECUTING: /usr/local/share/android-sdk/emulator/emulator @dev33_google_apis_x86_64_Pixel_5 -no-window -no-audio -gpu auto-no-window -read-only -no-boot-anim -id :app:pixel5api33googleDebugAndroidTest CURRENT_WORKING_DIRECTORY: (略) START_TIME: 2022-10-04 22:26:40.754 START_TIME-NANOS: 2022-10-04 22:26:40.754965000 ENVIRONMENT: (略) ANDROID_AVD_HOME=/Users/sumio.toyama/.android/avd/gradle-managed ***************************************** STDOUT/STDERR BELOW =================== INFO | Android emulator version 31.3.10.0 (build_id 8807927) (CL:N/A) (略) =================== END_TIME: 2022-10-04 22:28:27.392 END_TIME-NANOS: 2022-10-04 22:28:27.392521000 DURATION: 106637ms EXIT CODE: 0
ENVIRONMENT欄に書かれているANDROID_AVD_HOME環境変数を指定しつつ、EXECUTING欄に書かれているコマンドを実行すると目的のエミュレータを起動できます。
ただし、このファイルに記載されているコマンドラインオプションのままだとエミュレータの画面が表示されないため、-no-windowオプションは外して起動してください。
起動したエミュレータを操作した後の状態を永続化したいときは-read-onlyオプションも外す必要があります。
両方のオプションを外した場合、このemulator.1.okの例だと目的のAVDでエミュレータを起動するコマンドは次のようになります。
env ANDROID_AVD_HOME=/Users/sumio.toyama/.android/avd/gradle-managed \ /usr/local/share/android-sdk/emulator/emulator @dev33_google_apis_x86_64_Pixel_5 \ -no-audio -gpu auto-no-window -no-boot-anim -id :app:pixel5api33googleDebugAndroidTest
まとめ
DroidKaigi 2022で発表した「Gradle Managed Virtual Devicesで変化するエミュレータ活用術」の内容から、 開発PC上でGradle Managed Devices(GMD)を試すのに必要な部分を抜粋して紹介しました。
DroidKaigi 2022のセッションでは、ここで触れられていない次の内容についても説明しています。 より深くGMDに触れてみたい方は、是非そちらもご覧ください。
- GMDの使い方
- 複数のデバイスをまとめてテストできるデバイスグループの使い方
- Tips
- デバイスの言語を(日本語などの)英語以外の言語に変更してからテストを実行する
build.gradleでは設定できない項目(ストレージ容量など)を変更する- テストを録画する
- GMDで使うエミュレータが不安定になったときにCold Bootする
- GMDで使うエミュレータをキッティングする
- 複数のデバイスをまとめてテストすると動作が不安定になる場合の回避策
- テストの種類別GMD活用シーン
- Robolectricが必要なLocal Testの移行
- UIテスト
- スクリーンショットテスト
- CI環境で動かすときのポイント
個人的には、今回の登壇は久しぶりのオフライン登壇でした。 久しぶりの雰囲気に緊張しつつも、聴きに来て下さった皆さんの様子を見ながら話すことの楽しさを改めて実感しました。 このような機会を提供して下さったDroidKaigi 2022スタッフをはじめ、関係者のみなさんに感謝いたします。
宣伝
この記事を読んで「面白かった」「学びがあった」と思っていただけた方、よろしければTwitterやfacebook、はてなブックマークにてコメントをお願いします。
また DeNA 公式 Twitter アカウント @DeNAxTech では、Blog記事だけでなく色々な勉強会での登壇資料も発信してます。ぜひフォローして下さい! Follow @DeNAxTech