こんにちは、SWETでCI/CDチームの前田( @mad_p )です。 SWETではCI/CDチームの一員として、Jenkins運用のサポートや、CI/CD回りのノウハウ蓄積・研究をしています。
はじめに
先日開催されましたCEDEC 2022にて、Gitリポジトリの肥大化に対応した事例を発表しました。これはそのフォローアップ記事となります。以前に出した記事の続編でもあります。
発表資料は次の場所に置いていますので、参照してみてください。
- CEDiL(要登録): https://cedil.cesa.or.jp/cedil_sessions/view/2600
- Speaker Deck: https://speakerdeck.com/dena_tech/kaorumaeda_cedec2022
Gitリポジトリの肥大化問題
前提となっている課題をおさらいしておきます。 Gitリポジトリは、コミットを重ねることで大きくなっていきます。 大きくなると、クローンにかかる時間や、クローン後の.gitを保存するためのディスク容量が多く必要になります。 その結果、CIの実行時間・CIマシンのディスク不足などの心配事が増えます。 特にディスク不足に関しては、.gitの容量とチェックアウトしたファイルの容量のダブルでディスク消費が増えるので注意が必要です。
Jenkinsマシン上では、同一のリポジトリをジョブ別の複数フォルダにクローンすることになります。 多くのジョブで活用されるリポジトリは、ディスク容量不足の原因となりやすいです。 今回の事例で節約対象としたJenkinsマシンでは、20か所以上にクローンされているリポジトリもあります。
今回紹介する事例について
今回紹介する事例の背景を少し説明したいと思います。 対象のJenkinsマシンは、あるモバイルゲームタイトルのCIを支えているものです。
そのゲームはリリースから数年経っていて、 毎月のイベントごとにアプリ更新とキャラクターの追加があります。 この月次のリリースに対応して、ソースコードやアセットのブランチを管理しています。
プロジェクト内の大きなリポジトリのトップ4はこんな感じです(クローン後の.gitの容量)。
- アセット(22GB)
- アセットバンドル(LFS利用、16GB)1
- アセットソース(15GB)
- アプリ(3.4GB)
一番大きいアセットリポジトリを使ったジョブが一番種類が多く、 大きさ×ジョブ数で、ディスクを多く必要とします。
Jenkinsマシンはオンプレ・クラウド合わせて15台くらいで運用しています。 macノードが、慢性的なディスク容量不足に悩まされていて、 ここをなんとかしたいというのが動機です。
すでに紹介した対応方法と効果
前回のブログ記事で説明した方法を使って節約できた容量を紹介します。 ある1台のmacノードでの成果を調べてみました。
リファレンスを活用したクローンでは、.gitの、ディスク容量とダウンロード時間を節約できました。
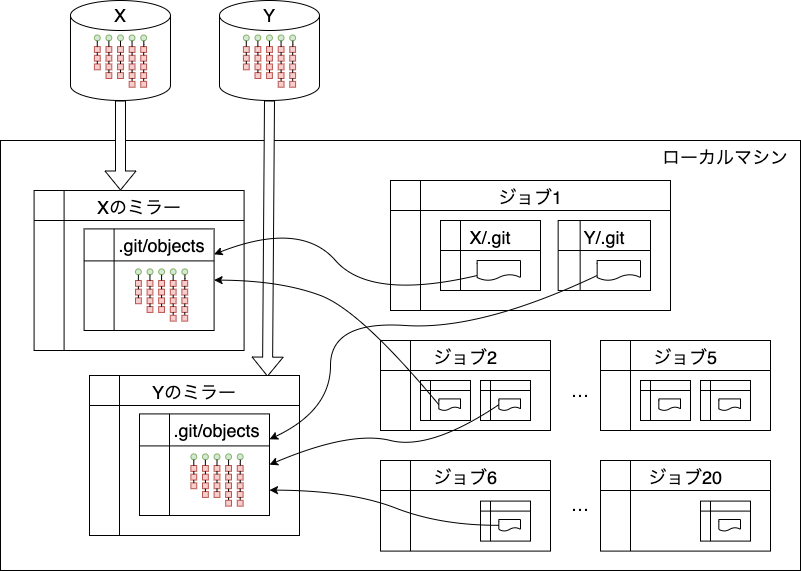
よく使うリポジトリの上位5つくらいを、リファレンスとして使うためのミラーとして用意しておきます。 定期的にフェッチするようにして、ある程度最新の状態になるように保っています。 Jenkinsのジョブでクローンするとき、 ミラーをリファレンスとして使うようにオプションを設定します。 これによって、20個以上の.gitをひとつにまとめることができました。
リファレンス設定のファイルを数えて調べたところ、 容量×参照数で、820GB程度の必要量を60GBにまとめることができています。 元々シャロークローンで足りていた部分もあると思うので、 実質の節約量は引き算した760GBとはいかず半分くらいかもしれません。 思っていたよりたくさん節約していたことがわかりました。
LFSローカルストレージの共有化では、 .git/lfsのディスク容量とダウンロード時間を節約できています。
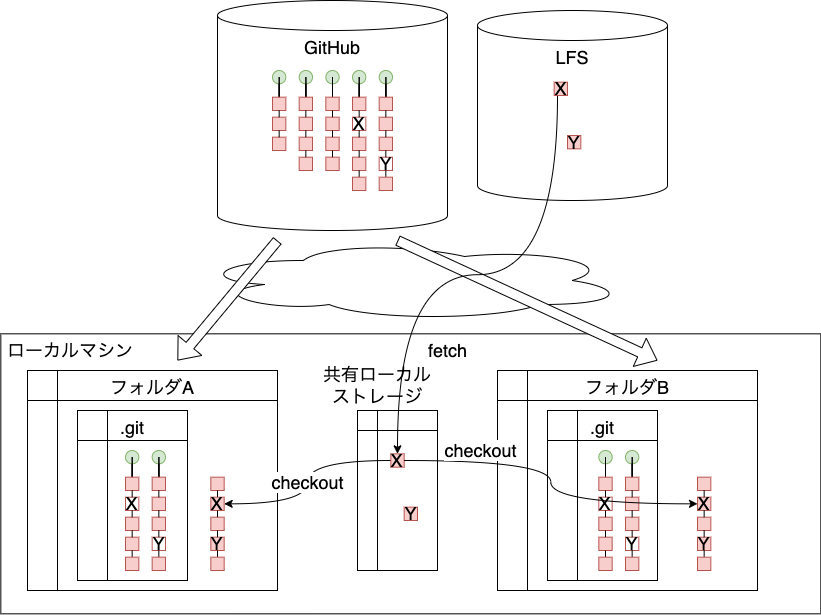
こちらは、現状での節約量を調べるのは難しかったので、 導入当時の記録を調べました。 複数フォルダの合計で90GB程度だったものが、まとめて20GBになったとありました。
copy-on-write機能を使ってディスクを節約した事例
それでは、本題のcopy-on-write活用について説明しましょう。
次の問題: チェックアウトしたファイルの容量が大きい
.gitの容量問題が解決したのですが、まだディスク残量が厳しい状況でした。 次の要因としては、チェックアウトしたワーキングツリーの容量が大きそうです。
どんなデータがJenkinsマシンのディスク内で容量を使っているかを調査してみました。 その結果、ジョブ内で参照するアセットデータが大きいとわかりました。 特に、キャラクターのモデルやモーションのデータが大きいです。 スパースチェックアウトが使えないかな、と思いましたが、 キャラクターデータを部分的に扱うジョブというのはなく、 うまくいかなさそうです。 サウンドデータもリポジトリ容量は大きいですが、 ジョブは少なくディスク容量としてはそれほど気にならないです。 すべてのジョブがリードオンリーとは限らない使い方、ということもわかりました。
容量を使っているのは、キャラクターやモーションのデータということがわかりました。 アセットリポジトリからチェックアウトしたフォルダツリーには、 ファイルが4万個くらい入っていて、25GBくらいの容量になります。 これがジョブごとに別の場所にあり、全部で20組くらい、 合計すると500GB程度になっています。
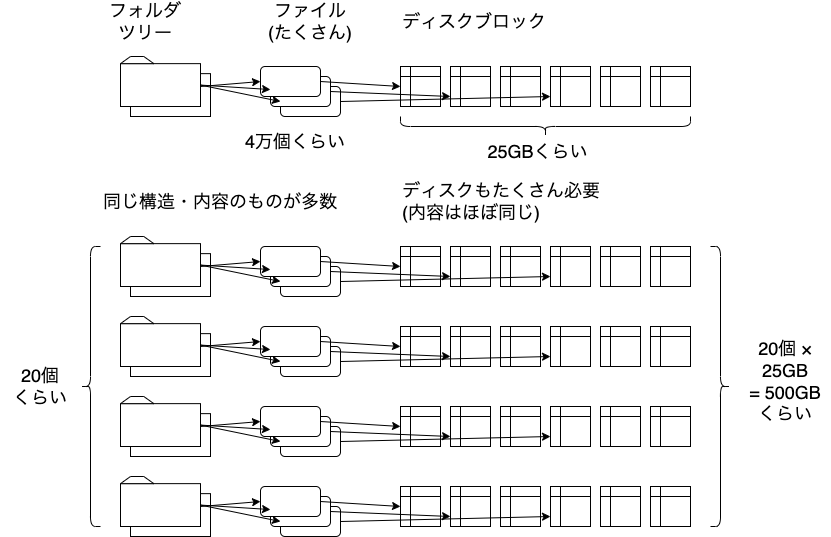
このように多数のコピーを持っているのは、Jenkinsマシンのうち、 macノードだけということもわかりました。 macOS特有の機能を使ってもいいから、なんとかしたいという思いがありました。
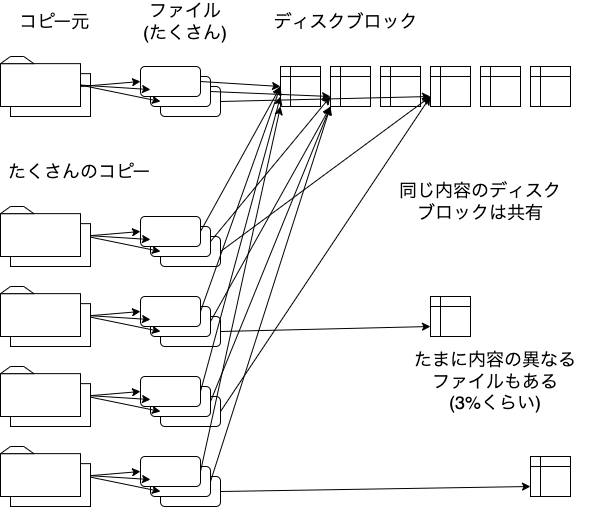
同一内容のファイルがたくさんコピーされているなら、まとめることができそうです。 macOSのAPFSというファイルシステムには、 同一内容のファイルのディスク領域だけを共有する機能があります。 copy-on-write動作をするので、リードオンリーと限らない場合でも使えそうです。
同一のディスクブロックをまとめられたら、 全体がこの図のようにできると思います。 これが理想の形です。
モデル/モーションデータの性質
ここで、対象となるモデル/モーションのデータがどんな性質を持っているかを考えてみます。
モデルとモーションは、開発が進むにつれて、 新規キャラクターのデータが追加されます。 一方で、すでに登場しているキャラクターのデータが修正されたり モーションが追加されることは、ゼロではないにしても、それほど多くはありません。 先に述べたように、これらのデータは月次リリースに対応してブランチ管理されています。 登場済みのキャラクターは、ブランチを切りかえても内容が変わらないことがほとんどです。
ジョブでは、このブランチ名をパラメーターとして処理を行うことが多いです。 毎月、その月のリリースのブランチだけを処理するわけではなく、 何か月か先のブランチに対してもCIを行っています。 このため、ジョブは実行するたびに別のブランチをチェックアウトしています。 具体的にどのファイルが上書きされるのかを予見することは難しいです。
UNIXのリンク機能
同一内容のファイルがたくさんあるときに、まとめるテクニックとして、 UNIXで古来から使われていた方法にリンクというものがあります。 macOSもUNIXの一種なので同じものが使えます。
ハードリンク、シンボリックリンクという2種類があり、 いずれも、データがリードオンリーの場合によく使われてきました。 macOSのcopy-on-write機能と比較するために、ちょっと復習してみます。
今回の用途をふまえて、次の2点に注意して比較してみましょう。
- 書きかえたときに、共有されている他のファイルに変更が反映されるか
- Gitにコミット、Gitからチェックアウトしたときにどうなるか
リンクの説明をするために、ファイルシステム内のデータ構造についてみてみましょう。 UNIXやLinux、macOSのファイルシステムは、だいたいこんな風になっています。
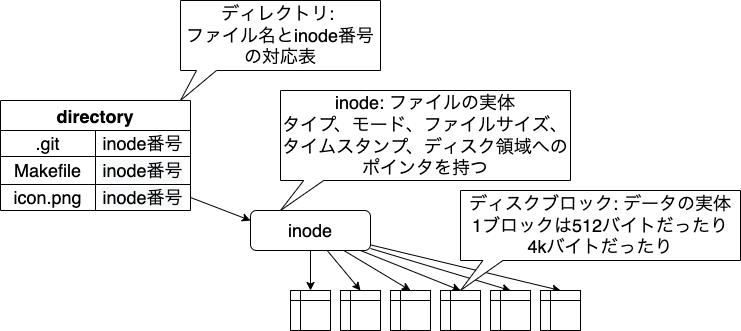
ファイルの実体は「inode」というデータ構造で管理されています。 ファイルのメタデータとディスクブロックの番号がここに記録されています。 実際のファイルひとつにinodeひとつが対応している感じです。
ファイルの内容は複数のブロックに分割して保存されています。 そのブロックの番号がinodeに記録されています。 じゃあファイル名はどこにあるんだ、というと、ディレクトリに入っています。 ディレクトリも実はファイルの一種です。 内容がファイル名とinode番号の対応表になっています。
ハードリンクは、ひとつのinodeに複数のファイル名をつける機能です。
ln コマンドで作ることができます。
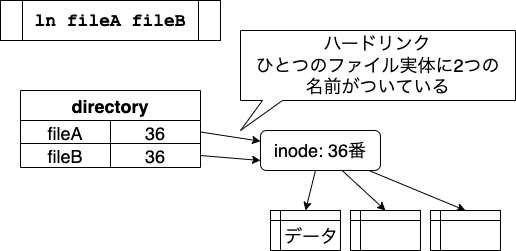
ひとつのファイルに2つの名前があるという状態になります。 片方を書きかえるともう一方にも変更が反映されます。 むしろ、反映されることを狙いたい場合に使われる方法です。
Gitは、「このファイルとこのファイルがハードリンクされている」というのを調べないので、 コミットしたりチェックアウトしたりすると、別のファイルとして扱われます。
シンボリックリンクは、 ln コマンドに -s オプションをつけると作ることができます。
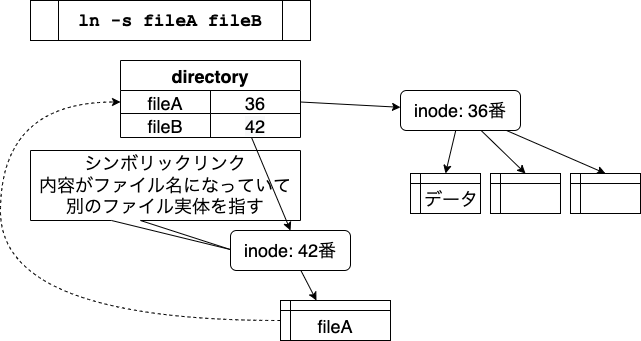
fileBのディスクブロックには「 fileA 」と書いてあって、
これをファイル名と見なしてfileAをさがし出し、
その内容をfileBの内容とする、という仕組みになっています。
片方を書きかえると、もう一方にも変更が反映されます。
Gitでは、シンボリックリンクを認識して、シンボリックリンクとしてコミットします。 チェックアウトするとシンボリックリンクとして作成されます。
以上の2つのリンク方式は、片方を書きかえるともう一方にも反映されるので、 今回対象とするJenkinsのジョブのように、 不用意に変更が反映されると困るという使い方には適していません。
macOSのcopy-on-write機能
macOSにある、copy-on-write機能の仕組みは、 これらのハードリンク、シンボリックリンクと比べてみると、理解しやすいです。
cp コマンドに -c オプションをつけると、この方法でファイルをコピーできます。
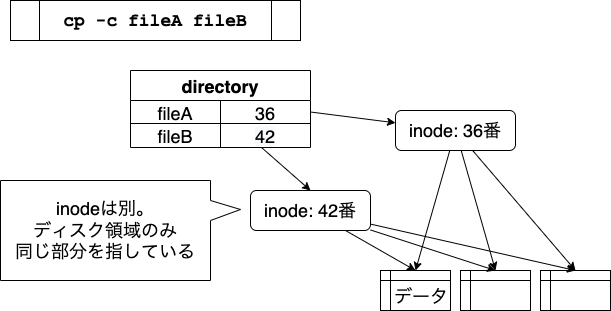
新しくinodeが作られ、ファイルの所有者やタイムスタンプなどは、独立して管理されます。 inodeから指しているディスク領域だけが、fileAとfileBで共有されます。
書きかえは片方にだけ反映されます。 ディスク領域を共有しているファイルの片方を書きかえると、 書き込みが発生した部分だけに、新たにディスクブロックが割り当てられます。
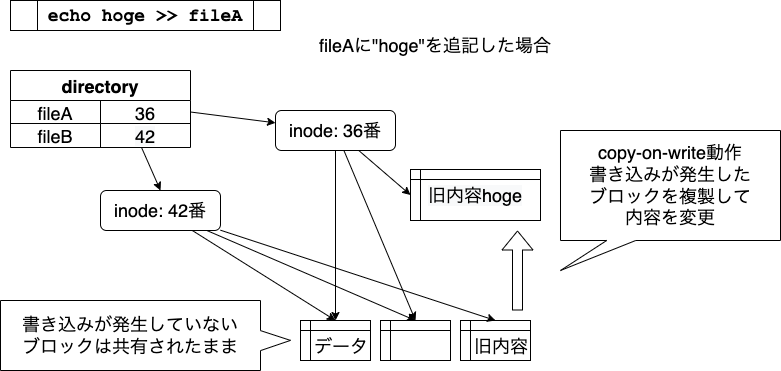
図では、fileAの末尾に「 hoge 」と追記した状態を表わしています。
fileAとfileBで共有していたディスクブロックのうち、
末尾に対応するブロックだけが新しいブロックにコピーされて、
hoge が追記されます。
この動作は、「write」するときに「copy」するので、 「copy-on-write」と呼ばれています。 この新しいブロックは、fileAからだけ参照されます。 結果として、fileAとfileBは別の内容のファイルになりますが、 内容が同じ部分ではディスク領域を共有している、ということになります。
このような動作は、今回の用途にはぴったりです。
予備実験、効果見積り
copy-on-writeの仕組みを使って、ディスクの節約はできそうでしょうか?
別のディレクトリにクローンした、同じ内容のファイルをまとめたとして、 次のチェックアウトで上書きされて、別のディスク領域に戻ってしまわないでしょうか? ブランチを切りかえても内容が変わらない場合、 ディスク領域の共有が維持されることを期待します。
また、copy-on-writeで領域をまとめるとき、 どれとどれが同一内容のファイルであるか特定できるでしょうか? フォルダツリーが同じ構造をしていれば、 同じファイル名のもの同士を対応させて調べられます。 前述した、リファレンス用にミラーしているフォルダを使って、 ツリー同士を比較できそうです。
節約できそうか調べるため、予備実験と効果見積りをしました。
ブランチを切りかえてチェックアウトしてみて、
更新のないファイルが上書きされるか調べました。
ls コマンドに -i オプションをつけると、inode番号を表示できます。
inode番号とタイムスタンプを調べると、上書きされないことがわかりました。
たくさんコピーがあると言いましたが、 どれくらい同一内容のファイルがあるのかも調べて、 効果の見積りをしました。 ミラーとジョブのツリーをつき合わせて内容を比較しました。 100万個くらいあるファイルのうち97%程度が、 対応するミラーのファイルと同一内容であり、 全体としては500GB程度を節約できそうだ、ということがわかりました。
また、この調査だけで10時間以上がかかってしまいました。 ディスク領域をまとめる処理を一度に全部やろうとすると、 24時間で終わらなさそう、現実的でない、ということもわかりました。
copy-on-writeにどんなリスクがあるのかもこの時点で検討しています。
- duなどのファイル容量調査ツールでは、別のinodeは別のディスク領域を使っていると計算される
- 「duで測定したディレクトリごとのディスク容量の合計」と「dfで見たディスク容量」が一致しなくなる
- copy-on-write活用によってどれくらいの節約になったか、効果測定が難しい
- 2つのファイルが共有しているかは、後述のapfs-clone-checkerで調べられる
- 領域共有が解除されるような操作によって急にディスク領域が必要になる
- ディスクの残り容量が十分にあると思っていたら、急にディスクフルになってしまう可能性がなくはない
- バックアップは正常に取れるが、リストアしようとしたらディスクに入り切らないという可能性もある
実装
予備実験の結果をふまえて、ディスク領域を共有するジョブを作成しました。 20個あるツリーのうち、1日に2個ずつ選んで処理します。 10日間で全ツリーに対して1回ずつ処理が終わり、 その後はまた最初から処理される、ということを狙っています。
ミラーにあるツリーを比較元として、ファイル内容が同一であるか調べます。
内容が同じで、かつ共有処理がまだされていなければ、
ミラーのファイルを cp -c して、処理対象のファイルの代わりに置きます。
これをたくさんのツリーに対して順に行えば、
「ミラーのディスク領域を共有したツリー」が増えていって、
いつか全部のディスク領域が共有できるというわけです。
どれくらいのファイルを処理したか、統計情報も出力するようにしました。
「2つのファイルが、すでにディスク領域を共有しているかどうか」は、 調べられるツールがあったので、これを使っています。
試験運用
このように作ったジョブを、1か月程度運用してみた結果です。 ディスク領域が共有できているのは、96万ファイル中39万ファイル、約200GB(40%程度)、ということがわかりました。
| 未共有 | 共有済 | 共有不可 | 合計 | |
|---|---|---|---|---|
| ファイル数 | 513,539 | 388,005 | 59,176 | 960,720 |
| 容量(GB) | 273.28 | 201.60 | 11.22 | 486.10 |
予備実験のときの見積りの半分くらいしか効果が出ていないです。これはなぜなんでしょう?
トラブルシューティング
効果が出ない理由として2つを予想しました。
- ジョブの中で、予備的に一度消してから、チェックアウトし直している
- 別ブランチをチェックアウトするときに書きかえられているファイルが多い
これを調べるために、ファイルが書きかえられた瞬間を見張りました。 1分に1回、lsコマンドでファイルのタイムスタンプを表示します。 ファイルが書きかわった時刻が分かるので、 そのときに実行されていたJenkinsジョブと、 ジョブの中のどのコマンドだったかを調べました。
こうやって調べた結果、わかったことを元に対策していきます。
予備的なクリア
「予備的に全クリア」しているジョブはなさそうでした。
ブランチを削除するツール
ひとつ原因がわかったのは、「ブランチを削除するツール」が悪さをしていたことです。
ブランチを消すとき、現在のワーキングツリーがそのブランチにいると、
git branch コマンドが、エラーになってしまいます。
これを回避するために、
「とりあえずmasterブランチを1回チェックアウトする」という動作をしていました。
このmasterブランチがとても古く、
多くのファイルが上書きされていました。
対策は簡単です。
masterをチェックアウトする代わりに、
git checkout --detach HEAD というコマンドを実行すればよいです。
タグをチェックアウトしたときと同様の状態になり、安全にブランチを削除できます。
アプリビルド
別の原因として、アプリビルドのジョブがありました。 アプリは、チュートリアルで必要なアセットのみを選んでビルドする必要があります。 必要ないアセットは、いったんチェックアウトした後、削除する処理になっていました。 対策として、このジョブはディスク領域の共有をあきらめて処理対象から外しました。
git reset --hard の挙動
もうひとつ面白かった原因は、ワーキングツリーをブランチの内容に合わせるため、
git reset --hard コマンドを使っていたことでした。
cp -c したファイルと置きかえた直後に git reset すると、
内容が同一かどうか調べず、常に上書きされてしまうことがわかりました。
git checkout では、内容が同一の場合には上書きされません。
対策としては、一度 git status を行っておけば、
git reset しても上書きされないことがわかりました。2
その他の工夫
そのほかに、ツリーを単位として、処理済みかどうかを素早く予想する方法を思いついたので、 日次のジョブに工夫を入れました。 古くから存在していて、更新されそうもないキャラのモデルファイルをひとつ選びます。 処理対象ツリーごとに、このファイルが共有処理済みかどうか調べます。 共有されていなければ、そのツリー全体がおそらく未処理なので、優先して処理します。 このファイルが共有済みであれば、ツリー全体はおそらく処理済みですが、確実とはいえないので、 低優先度ながら処理するようにしました。
結果
このような改善をして、運用をさらに1か月続けた結果です。
| 未共有 | 共有済 | 共有不可 | 合計 | |
|---|---|---|---|---|
| ファイル数 | 81,236 | 773,185 | 15,440 | 869,861 |
| 容量(GB) | 43.67 | 412.63 | 8.21 | 464.51 |
87万ファイル中の 77万ファイル 、 約400GB(88%) のディスク領域を節約できました。 対策の中で処理対象から外したジョブもあるので、 見積り段階と比べると分母も減っています。
下のグラフは、効果の大きかった4台のマシンの空き容量監視画面です。
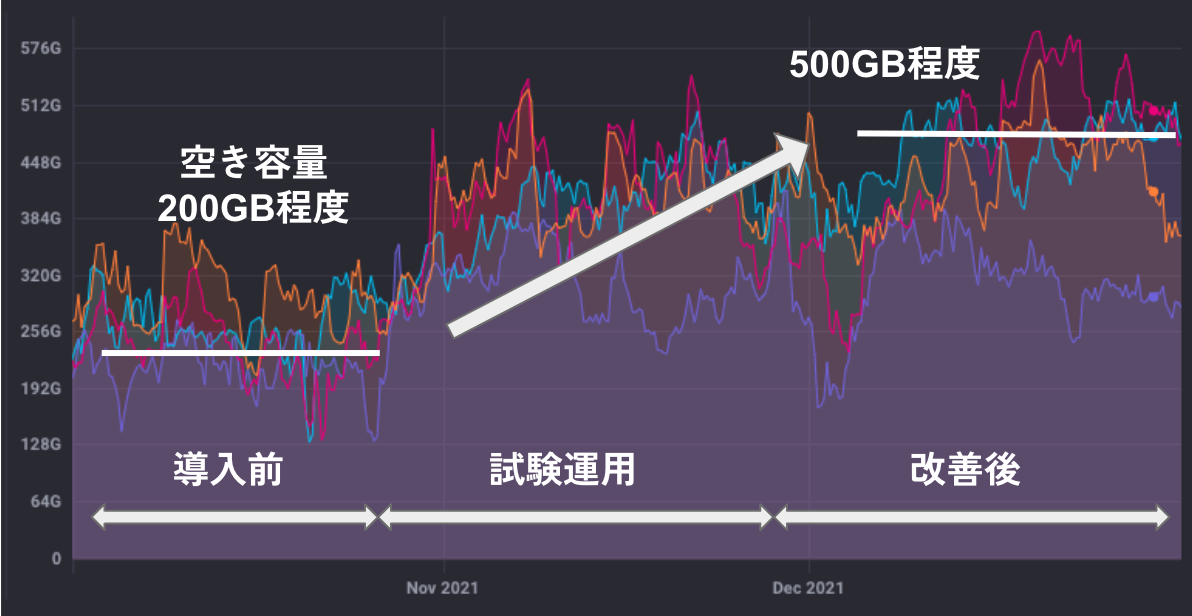
導入前、200GB程度だった空き容量が、 試験運用のときは400GB程度、 改善後は500GB程度になっているのがわかります。 他の要因もあるので、 400GB空き容量が増えた、とはいきませんでしたが、 copy-on-writeの効果としては十分な節約ができたと思います。
当初の状態と比べてみましょう。
これが、こうなりました。
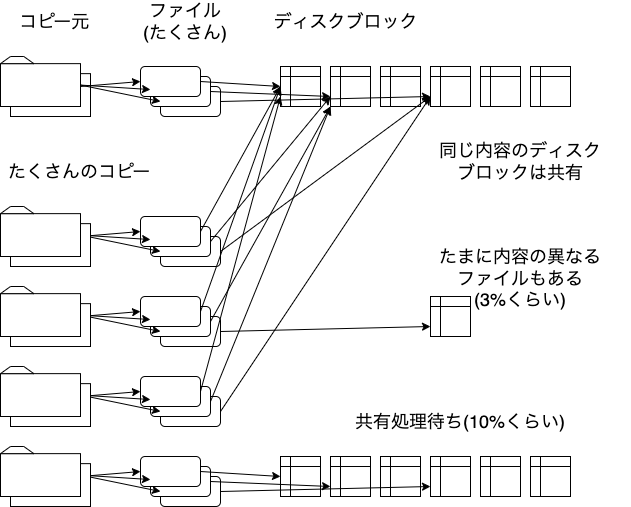
理想形との違いは、未処理のツリーが、10%くらいは常にありそう、ということです。
まとめ
Jenkinsのmacノード上で、チェックアウトしたデータの容量が多く、慢性的なディスク不足に悩んでいました。 容量の大きいデータを特定し、その性質を調べました。 copy-on-write機能が使えそうだと思いついて、 本当に使えるのか、予備実験をして効果を見積りました。 実装して試験運用すると、効果がいまいちでした。 その原因をさぐって対策した結果、見積りに近い効果が得られました。 gitコマンドの動作の違いなどがわかって面白かったです。
前回のブログで紹介した工夫と、今回紹介したブログの工夫を合わせて、 .gitの容量とチェックアウトしたファイルの容量の両面から、ディスク節約を行えました。
copy-on-write機能は、大きなフォルダ全体のコピーを素早く作りたいときなどにも役立ちます。
たとえば、自分の開発用マシン上で、すでにクローン済みのフォルダとは別にもうひとつクローンしたい場合に使えます。
ワーキングツリーと.gitをまとめて全部 cp -ac cloned_folder cloned_folder2 のようにコピーすると、
時間とディスク容量の両方を節約できます。
JenkinsやGitを使わない場合でも、便利な場面が多いと思います。
ぜひ活用してみてください。
宣伝
この記事を読んで「面白かった」「学びがあった」と思っていただけた方、よろしければTwitterやfacebook、はてなブックマークにてコメントをお願いします。
また DeNA 公式 Twitter アカウント @DeNAxTech では、Blog記事だけでなく色々な勉強会での登壇資料も発信してます。ぜひフォローして下さい! Follow @DeNAxTech
-
LFSについては前回の記事のLFS (Large File Storage) の活用の項で解説しています↩
-
git statusで作成したインデックス情報とファイルの状態が異なる場合、git checkoutではファイルの内容が変わっているのか調べてくれるのに対し、git resetでは調べてくれないようです。インデックスにどんな情報が入っているかは、GitHubブログのこの記事の「Phase 1: refresh_index」の項に解説があります。inode番号も入っていますね。↩











